Synthetic Casting Directors: How AI Models Are Being Trained on “Vibe” and “Energy”
1/23/20265 min read
Fashion has always had an invisible layer that separates “a person in clothes” from “a model.” Casting directors don’t just select faces—they select attitude. The quiet menace of a 90s grunge walk. The unapologetic precision of a high-glam gaze. The way someone holds a shoulder line, pauses at the end of a runway, or turns a glance into a statement.
For the last couple of years, most generative fashion work has been stuck at the “generic pretty” stage: attractive faces, decent lighting, a plausible pose. It’s useful for volume, but it’s not castable. It doesn’t feel editorial. It doesn’t carry the energy that makes a brand instantly recognizable.
Now the industry is shifting toward something more specific: synthetic casting—training AI models not only to look realistic, but to reliably produce distinct editorial “attitudes.” In practice, that means fine-tuning models on highly curated aesthetic datasets so they can reproduce consistent, controllable vibes (e.g., “90s grunge,” “high-glam,” “quiet luxury,” “athletic edge,” “noir muse”) the way a real casting director would.
For Noir Starr Models, this is the heart of the value proposition: not random AI faces, but a roster of repeatable identities plus repeatable energy—editorial consistency at scale.
This article breaks down the technical side of that shift: how “vibe” becomes data, how “energy” becomes supervision, and how walk/gaze/attitude can be pushed into a model’s weights (and—equally important—into the production pipeline around the model).
First: what do we actually mean by “vibe” and “energy”?
In technical terms, “vibe” is not magic. It’s a bundle of correlated signals—some visual, some temporal, some contextual:
Pose language: hip angle, shoulder pitch, contrapposto, limb tension, negative space in the frame
Gaze behavior: eye direction, eyelid aperture, head tilt, micro-expressions, “soft focus” vs “piercing”
Styling grammar: hair texture, makeup finish, accessories, silhouette choice
Lighting + color science: contrast ratio, specular behavior, grain, halation, shadow softness
Camera + composition: focal length look, perspective, crop conventions, motion blur
Temporal rhythm (video/runway): stride length, cadence, pause timing, torso rotation, arm swing
A general image model can mimic some of these patterns occasionally. A fashion-trained “vibe model” aims to produce them reliably, under control, across sets.
Why generic AI faces aren’t enough anymore
Generic models are trained on broad internet imagery. That gives them two big weaknesses for fashion:
They average aesthetics.
Even when prompted for an editorial vibe, the model often collapses back to the mean: safe beauty lighting, generic posing, familiar facial styling, “Instagram pretty.”They don’t preserve a brand’s casting logic.
Fashion brands don’t just want “high-glam.” They want their high-glam: a specific intensity, shadow language, styling restraint (or excess), and camera discipline.
This is why the market is moving from “prompting harder” to fine-tuning and aesthetic adaptation.
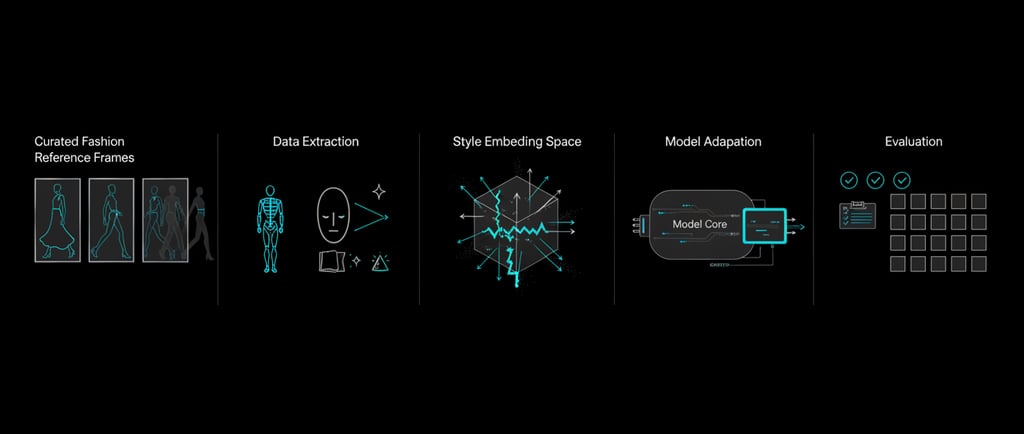
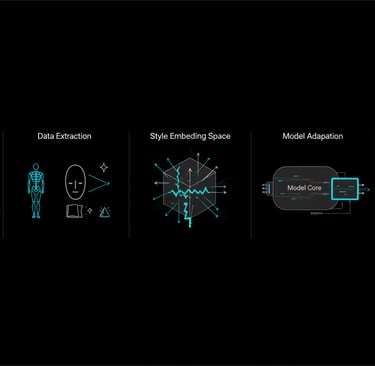
How do you encode “vibe” into weights?
There are two broad approaches—and most serious fashion pipelines use both:
A) Put the vibe into the model (training / fine-tuning)
This is about changing the model’s internal distribution so “the right vibe” becomes the default behavior.
B) Put the vibe into control (conditioning / pipelines)
This is about controlling the generation so the vibe emerges consistently without over-baking it into the weights.
Think of it as: learn the taste + control the outcome.
The data problem: “vibe” training starts with ruthless curation
If you want “90s grunge,” you don’t throw 50,000 random photos labeled “grunge” into training. That creates a muddy aesthetic. You curate narrowly:
era-correct reference sets (lighting, grain, makeup conventions)
consistent runway/editorial camera language
body language examples that actually read as grunge (not just flannel)
exclusions: anything that breaks the vibe, even if it’s “cool”
The quality of vibe fine-tuning is usually limited less by model architecture and more by dataset discipline.
For Noir Starr-style work, the dataset is often curated around:
lighting rules (noir contrast, controlled highlights)
pose language (editorial tension, clean silhouette)
garment realism constraints
consistent beauty finish (skin texture, not plastic)
Labeling vibe: from subjective taste to usable supervision
You can’t train a model on “energy” without turning it into some kind of label or preference signal. There are three common strategies:
1) Attribute labels (structured tags)
You build a schema like:
gaze: direct / off-camera / downcast
expression: neutral / smirk / fierce / soft
pose tension: relaxed / taut / angular
era cues: 90s grain / modern clean / retro flash
lighting: hard key / soft key / edge-lit / chiaroscuro
styling: glossy glam / matte grunge / minimal
This is labor-intensive, but it creates controllable knobs.
2) Pairwise preference data (ranking)
Instead of labeling what something “is,” you label what’s “more vibe-correct.”
Example: show annotators two images and ask:
Which one is more “high-glam gaze”? Which one is “more Noir Starr”?
This data can train:
a reward model (a vibe scorer), or
direct preference optimization that nudges generation toward the preferred aesthetic.
This works surprisingly well because humans are better at ranking vibe than defining it.
3) Embedding-based clustering (semi-supervised)
You use a strong image/text embedding model to cluster references into coherent aesthetic pockets, then:
name clusters,
refine with human reviews,
and treat clusters as vibe classes or style tokens.
This is how you go from “vibes as taste” to “vibes as categories.”
Encoding a “high-glam gaze” (the technical anatomy of an attitude)
A “high-glam gaze” isn’t just “eyes looking at camera.” It’s a compound of:
eyelid openness and symmetry
eye-line direction relative to lens
head tilt (often subtle)
brow tension and mouth neutrality
highlight placement (catchlights, cheek speculars)
camera distance/focal length look (glam is often unforgiving here)
makeup finish and lash definition cues
shadow discipline (glam dies in messy shadows)
How it becomes training signal:
Curate close-to-camera editorial frames that match the exact gaze intensity you want.
Annotate gaze vectors (explicitly via keypoint detection, or implicitly through vibe ranking).
Fine-tune using an adapter (e.g., LoRA-style adaptation) so the model learns the correlation between prompt cues and those facial geometry + lighting cues.
Add a vibe scorer (learned reward model) that penalizes “dead eyes,” asymmetry, or overly soft expression drift.
Lock identity so you’re not trading vibe for face instability.
This is why “vibe” models are often built as small adapters attached to a strong base model: you’re learning a targeted aesthetic direction, not relearning the world.
Encoding a “90s grunge walk” (motion, not just look)
A walk is temporal. If you only train on stills, you’ll get “grunge styling” but not “grunge movement.”
To encode walk energy, you need data that contains time:
runway video clips
multi-frame sequences of the same stride
motion capture or pose keypoint sequences
What gets learned:
stride cadence (tempo)
hip sway vs stiffness
shoulder roll
arm swing amplitude
head stability (detached cool vs engaged performance)
end-of-runway pause behavior
How it goes into a model:
Extract pose keypoints per frame (skeleton sequences).
Represent motion as trajectories (how joints move over time).
Train/condition a motion model (or a video diffusion/transformer) on these sequences with vibe conditioning.
Tie motion to appearance via multimodal training: the same “grunge” tag conditions both the walk and the styling/lighting language.
Even if the end product is still images, motion data helps because it teaches the model how bodies carry garments—the fabric swing and posture tension that reads as authentic.
Multimodal vibe training: vibe lives across text, image, and motion
The best aesthetic fine-tuning isn’t “image-only.” It learns alignment across:
text descriptors (editorial language)
images (appearance)
video or pose sequences (movement)
garment metadata (silhouette, fabric behavior)
This is how you get a model that doesn’t just output “grunge”—it outputs:
grunge pose language,
grunge lighting/grain,
grunge movement cues,
and grunge styling cohesion.
The production stack: vibe isn’t only in weights
Even with perfect fine-tuning, fashion systems still need control:
pose control to preserve attitude
lighting control to keep noir consistency
identity locking to keep the “cast”
QA to reject vibe drift
This is where Noir Starr’s “synthetic casting director” concept becomes practical: you’re not generating one image—you’re generating a castable set with consistent energy across a campaign.
Evaluation: how do you measure “energy” without fooling yourself?
Teams that do this well use multi-layer evaluation:
Casting board review: humans rank outputs like a real casting session
Vibe classifier / scorer: a learned model that predicts vibe-correctness
Consistency checks: identity stability, pose stability, garment realism
Drift tests: does the vibe remain consistent across 50 generations? across weeks?
A single “great image” is not the goal. The goal is repeatable casting-grade outputs.
Why this matters now (and why it’s a moat)
As AI fashion content scales, “realism” becomes table stakes. The winners differentiate on:
editorial attitude
brand-specific energy
casting consistency
aesthetic control at scale
That is exactly what synthetic casting is: turning taste into a trainable, repeatable system.
Luxury
Elevate your brand with our exclusive AI models.
Contact us
Exclusivity
© 2026. All rights reserved.
(609) 901-8073